
I have a longstanding interest in the concept of emergence as a way of explaining a wide range of human ideas and the natural world. We have this incredible algorithm of evolutionary change that creates novel life forms. We have, according to mainstream materialist accounts of philosophy of mind, a consciousness that may have a unique ontology (what really exists) of subjective experiencers and qualia and intentionality, but that is also somehow emergent from the meat of the brain (or supervenes or is an epiphenomenon, etc. etc.) That emergence may be weak or strong in various accounts, with strong meaning something like the idea that a new thing is added to the ontology while weak meaning something like we just don’t know enough yet to find the reduction of the concept to its underlying causal components. If we did, then it is not really something new in this grammar of ontological necessity.
There is also the problem of computational irreducibility (CI) that has been championed by Wolfram. In CI, there are classes of computations that result in outcomes that cannot be predicted by any simpler algorithm. This seems to open the door to a strong concept of emergence: we have to run the machine to get the outcome; there is no possibility (in theory!) of reducing the outcome to any lesser approximation. I’ve brought this up as a defeater of the Simulation Hypothesis, suggesting that the complexity of a simulation is irreducible from the universe as we see it (assuming perfect coherence in the limit).
There is also a dual to this idea in algorithmic information theory (AIT) that is worth exploring. In AIT, it is uncomputable to find the shortest Turing Machine capable of accepting a given symbol sequence.… Read the rest




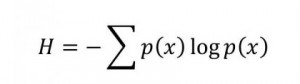 Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.