 Even given the basic conundrum of how deep learning neural networks might cope with temporal presentations or linear sequences, there is another oddity to deep learning that only seems obvious in hindsight. One of the main enhancements to traditional artificial neural networks is a phase of supervised pre-training that forces each layer to try to create a generative model of the input pattern. The deep learning networks then learn a discriminant model after the initial pre-training is done, focusing on the error relative to classification versus simply recognizing the phrase or image per se.
Even given the basic conundrum of how deep learning neural networks might cope with temporal presentations or linear sequences, there is another oddity to deep learning that only seems obvious in hindsight. One of the main enhancements to traditional artificial neural networks is a phase of supervised pre-training that forces each layer to try to create a generative model of the input pattern. The deep learning networks then learn a discriminant model after the initial pre-training is done, focusing on the error relative to classification versus simply recognizing the phrase or image per se.
Why this makes a difference has been the subject of some investigation. In general, there is an interplay between the smoothness of the error function and the ability of the optimization algorithms to cope with local minima. Visualize it this way: for any machine learning problem that needs to be solved, there are answers and better answers. Take visual classification. If the system (or you) gets shown an image of a coatimundi and a label that says coatimundi (heh, I’m running in New Mexico right now…), learning that image-label association involves adjusting weights assigned to different pixels in the presentation image down through multiple layers of the network that provide increasing abstractions about the features that define a coatimundi. And, importantly, that define a coatimundi versus all the other animals and non-animals.,
These weight choices define an error function that is the optimization target for the network as a whole, and this error function can have many local minima. That is, by enhancing the weights supporting a coati versus a dog or a raccoon, the algorithm inadvertently leans towards a non-optimal assignment for all of them by focusing instead on a balance between them that is predestined by the previous dog and raccoon classifications (or, in general, the order of presentation).… Read the rest
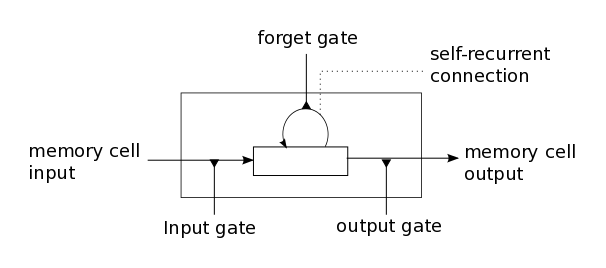




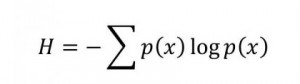 Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
