 Google’s translate has always been a useful tool for awkward gists of short texts. The method used was based on building a phrase-based statistical translation model. To do this, you gather up “parallel” texts that are existing, human, translations. You then “align” them by trying to find the most likely corresponding phrases in each sentence or sets of sentences. Often, between languages, fewer or more sentences will be used to express the same ideas. Once you have that collection of phrasal translation candidates, you can guess the most likely translation of a new sentence by looking up the sequence of likely phrase groups that correspond to that sentence. IBM was the progenitor of this approach in the late 1980’s.
Google’s translate has always been a useful tool for awkward gists of short texts. The method used was based on building a phrase-based statistical translation model. To do this, you gather up “parallel” texts that are existing, human, translations. You then “align” them by trying to find the most likely corresponding phrases in each sentence or sets of sentences. Often, between languages, fewer or more sentences will be used to express the same ideas. Once you have that collection of phrasal translation candidates, you can guess the most likely translation of a new sentence by looking up the sequence of likely phrase groups that correspond to that sentence. IBM was the progenitor of this approach in the late 1980’s.
It’s simple and elegant, but it always was criticized for telling us very little about language. Other methods that use techniques like interlingual transfer and parsers showed a more linguist-friendly face. In these methods, the source language is parsed into a parse tree and then that parse tree is converted into a generic representation of the meaning of the sentence. Next a generator uses that representation to create a surface form rendering in the target language. The interlingua must be like the deep meaning of linguistic theories, though the computer science versions of it tended to look a lot like ontological representations with fixed meanings. Flexibility was never the strong suit of these approaches, but their flaws were much deeper than just that.
For one, nobody was able to build a robust parser for any particular language. Next, the ontology was never vast enough to accommodate the rich productivity of real human language. Generators, being the inverse of the parser, remained only toy projects in the computational linguistic community.… Read the rest



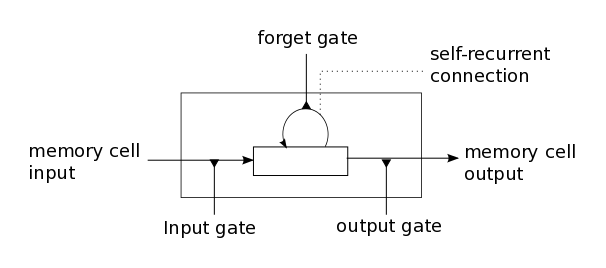



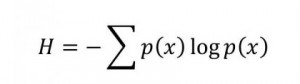 Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.