 Right-wing authoritarianism (RWA) and Social dominance orientation (SDO) are measures of personality traits and tendencies. To measure them, you ask people to rate statements like:
Right-wing authoritarianism (RWA) and Social dominance orientation (SDO) are measures of personality traits and tendencies. To measure them, you ask people to rate statements like:
Superior groups should dominate inferior groups
The withdrawal from tradition will turn out to be a fatal fault one day
People rate their opinions on these questions using a 1 to 5 scale from Definitely Disagree to Strongly Agree. These scales have their detractors but they also demonstrate some useful and stable reliability across cultures.
Note that while both of these measures tend to be higher in American self-described “conservatives,” they also can be higher for leftist authoritarians and they may even pop up for subsets of attitudes among Western social liberals about certain topics like religion. Haters abound.
I used the R packages twitterR, textminer, wordcloud, SnowballC, and a few others and grabbed a few thousand tweets that contained the #DonaldJTrump hashtag. A quick scan of them showed the standard properties of tweets like repetition through retweeting, heavy use of hashtags, and, of course, the use of the #DonaldJTrump as part of anti-Trump sentiments (something about a cocaine-use video). But, filtering them down, there were definite standouts that seemed to support a RWA/SDO orientation. Here are some examples:
The last great leader of the White Race was #trump #trump2016 #donaldjtrump #DonaldTrump2016 #donaldtrump”
Just a wuss who cant handle the defeat so he cries to GOP for brokered Convention. # Trump #DonaldJTrump
I am a PROUD Supporter of #DonaldJTrump for the Highest Office in the land. If you don’t like it, LEAVE!
#trump army it’s time, we stand up for family, they threaten trumps family they threaten us, lock and load, push the vote…
Not surprising, but the density of them shows a real aggressiveness that somewhat shocked me. So let’s assume that Republicans make up around 29% of the US population, and that Trump is getting around 40% of their votes in the primary season, then we have an angry RWA/SDO-focused subpopulation of around 12% of the US population.
That seems to fit with results from an online survey of RWA, reported here. An interesting open question is whether there is a spectrum of personality types that is genetically predisposed, or whether childhood exposures to ideas and modes of childrearing are more likely the cause of these patterns (and their cross-cultural applicability).
Here are some interesting additional resources:
The latter has a particularly good overview of RWA/SDO, other measures like openness, etc., and Twitter as an analytics tool.
Finally, below is some R code for Twitter analytics that I am developing. It is derivative of sample code like here and here, but reorients the function structure and adds deletion of Twitter hashtags to focus on the supporting language. There are some other enhancements like codeset normalization. All uses and reuses are welcome. I am starting to play with building classifiers and using Singular Value Decomposition to pull apart various dominating factors and relationships in the term structure. Ultimately, however, human intervention is needed to identify pro vs. anti tweets, as well as phrasal patterns that are more indicative of RWA/SDO than bags-of-words can indicate.
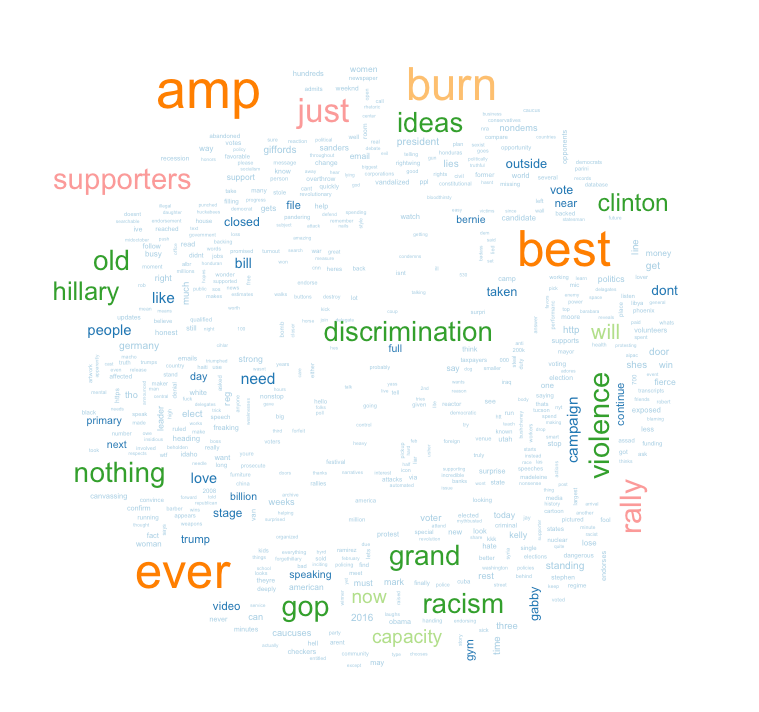
Also, here are wordclouds generated for #hillaryclinton and #DonaldJTrump, respectively. The Trump wordcloud was distorted by some kind of repetitive robotweeting that dominated the tweets.

require(twitteR)
require(tm)
require(SnowballC)
require(wordcloud)
require(RColorBrewer)
tweets.grabber=function(searchTerm,num=500,pstopwords=c(),verbose=FALSE){
#Grab the tweets
djtTweets <- searchTwitter(searchTerm, num)
#Use a handy helper function to put the tweets into a dataframe
tw.df=twListToDF(djtTweets)
RemoveDots <- function(tweet) {
gsub("[\\.\\,\\;]+", " ", tweet)
}
RemoveLinks <- function(tweet) {
gsub("http:[^ $]+", "", tweet)
gsub("https:[^ $]+", "", tweet)
}
RemoveAtPeople <- function(tweet) {
gsub("@\\w+", "", tweet)
}
RemoveHashtags <- function(tweet) {
gsub("#\\w+", "", tweet)
}
FixCharacters <- function(tweet){
iconv(tweet,to="utf-8-mac")
}
CleanTweets <- function(tweet){
s1 <- RemoveLinks(tweet)
s2 <- RemoveAtPeople(s1)
s3 <- RemoveDots(s2)
s4 <- RemoveHashtags(s3)
s5 <- FixCharacters(s4)
s5
}
tweets <- as.vector(sapply(tw.df$text, CleanTweets))
if (verbose) print(tweets)
generateCorpus= function(df,pstopwords){
tw.corpus= Corpus(VectorSource(df))
tw.corpus = tm_map(tw.corpus, content_transformer(removePunctuation))
tw.corpus = tm_map(tw.corpus, content_transformer(tolower))
tw.corpus = tm_map(tw.corpus, removeWords, stopwords('english'))
tw.corpus = tm_map(tw.corpus, removeWords, pstopwords)
tw.corpus
}
corpus = generateCorpus(tweets)
corpus
}
corpus.stats=function(corpus){
doc.m = TermDocumentMatrix(corpus, control = list(minWordLength = 1))
dm = as.matrix(doc.m)
# calculate the frequency of words
v = sort(rowSums(dm), decreasing=TRUE)
v
}
wordcloud.generate=function(v,min.freq=3){
d = data.frame(word=names(v), freq=v)
#Generate the wordcloud
wc=wordcloud(d$word, d$freq, scale=c(4,0.3), min.freq=min.freq, colors = brewer.pal(8, "Paired"))
wc
}
setup_twitter_oauth("XXXX","XXXX","XXXX,"XXXX")
djttweets = tweets.grabber("#DonaldJTrump", 2000, verbose=TRUE)
djtcorpus = corpus.stats(djttweets)
wordcloud.generate(djtcorpus, 3)
Have you considered topic modeling this data? R has the Latent Dirichlet Allocation capability built in as of 2012. For some good references Google “probabilistic topic models steyvers”.
Sure, I’ve used LDA in the past. The methods are not the primary challenge, however. Gathering the data and seeing whether there are strong RWA/SDO indicators at the phrasal level (pretty sure there are) is the main difficulty. One approach, per the second reference, is to use followers of a given person to increase likelihood of association between the tweeter and the person (and reduce spam). But better shallow parsing is likely needed, too. Word ngrams using log-likelihood scoring would be a simple approach.